Research
My research centers on building multimodal intelligence; machines that can perceive, reason over, and ground language in what they hear and see. Most of my recent work focuses on Large Audio(-Visual)-Language Models: how they fuse audio, vision, and text, where that fusion fails (temporal grounding, modality bias), and how to post-train them for stronger reasoning over long and complex real-world videos.
Alongside this, I study reasoning and reinforcement learning in language agents; what cooperative and strategic capabilities emerge in LLMs, and what actually transfers when RL trains an agent. My earlier work at IIT Madras and on the Govt. of India Bhashini project built robust multilingual speech systems for low-resource Indian languages.
Audio Understanding and Processing
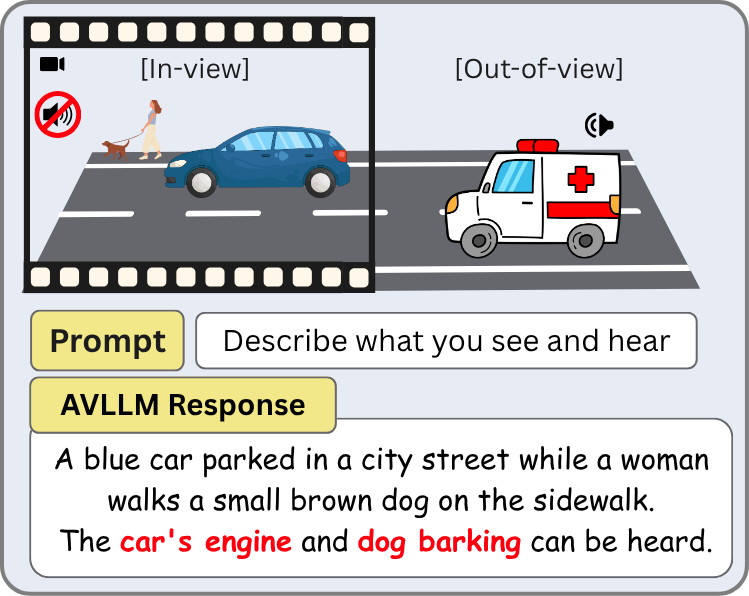
Do Audio-Visual Large Language Models Really See and Hear?
AVLLMs exhibit a strong vision bias in audio understanding, hallucinating sounds from what they see rather than what they hear. We conduct mechanistic interpretability experiments showing that rich audio semantics exist internally, cross-modal transfer occurs in mid-to-deep layers where vision dominates, and this bias likely stems from vision-centric training.
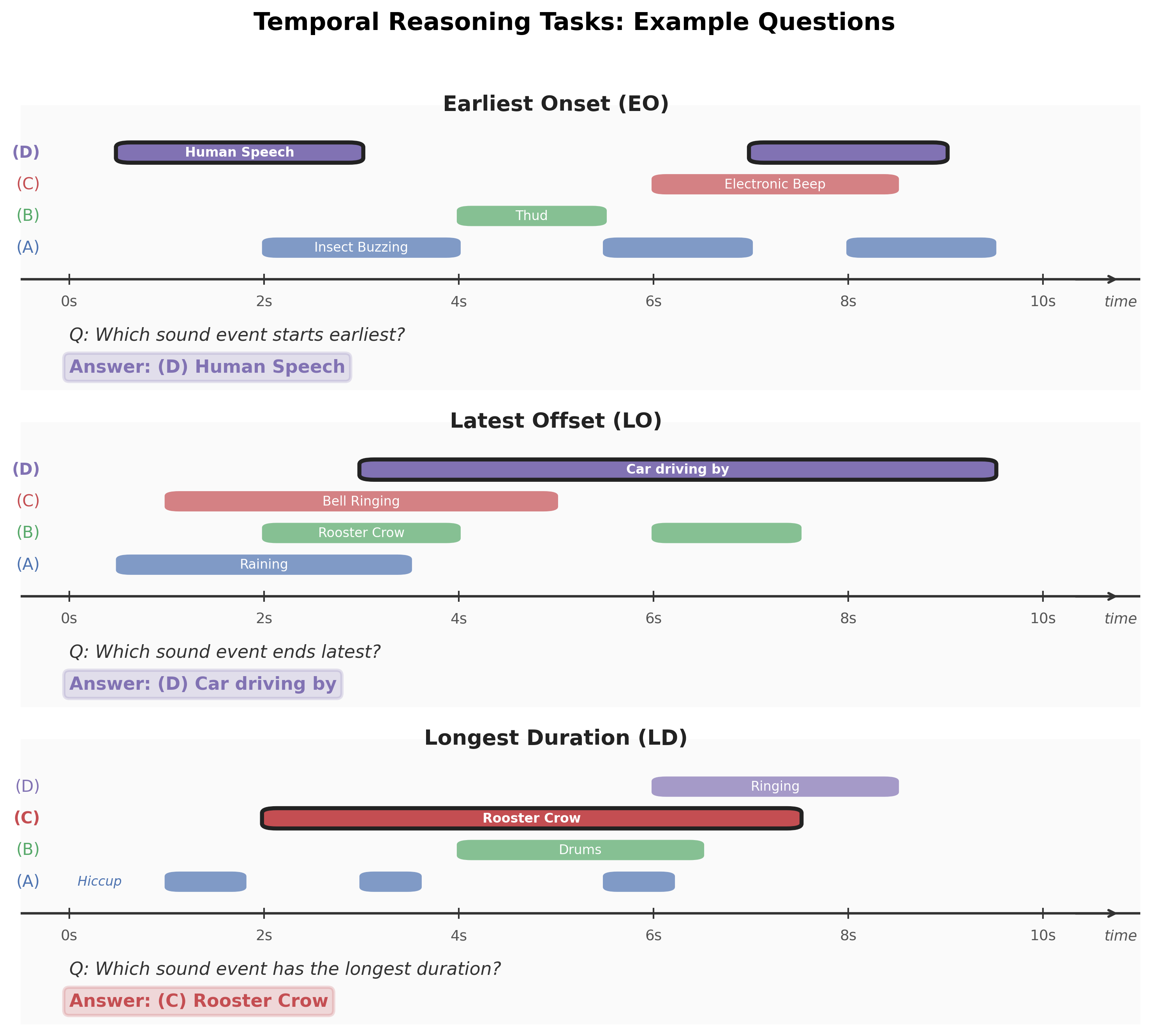
A Closer Look at Failure Modes in Temporal Understanding of Large Audio-Language Models
LALMs consistently fail at foundational temporal tasks — identifying which sound started first, ended last, or lasted longest. We introduce a 1,657-question benchmark for mechanistic diagnosis and find that the problem isn't just modality imbalance: redistributing attention across audio tokens (scaling) outperforms simply increasing audio attention (upweighting). Layer-targeted scaling improves accuracy by 3.2% with no fine-tuning.
Audio-Visual Flamingo: Open Audio-Visual Intelligence for Long and Complex Videos
An open audio-visual model built to understand long and complex videos, jointly reasoning over speech, sound, and what's on screen across extended temporal contexts — advancing open audio-visual intelligence beyond short clips.

Audio Flamingo Next: Next-Generation Open Audio-Language Models for Speech, Sound, and Music
The next generation of open audio-language models spanning speech, sound, and music — pushing open audio intelligence with stronger reasoning and broader coverage across the full audio spectrum.

Massive Multi-Task Omni Understanding and Reasoning Benchmark for Long Real-World Videos
A massive multi-task benchmark for omni understanding and reasoning over long, real-world videos, stress-testing models across audio, vision, and language jointly rather than in isolation.

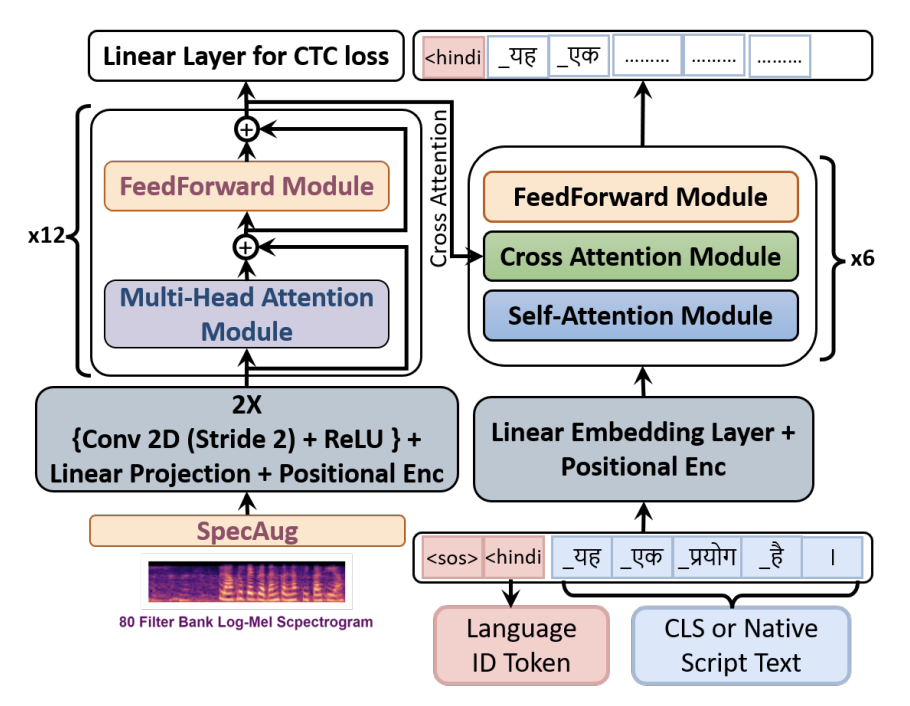
The Tag-Team Approach: Leveraging CLS and Language Tagging for Enhancing Multilingual ASR
We leverage CLS tokens and explicit language tagging to improve multilingual ASR across Indian languages, boosting recognition for low-resource languages over the corresponding monolingual baselines.
Natural Language Processing
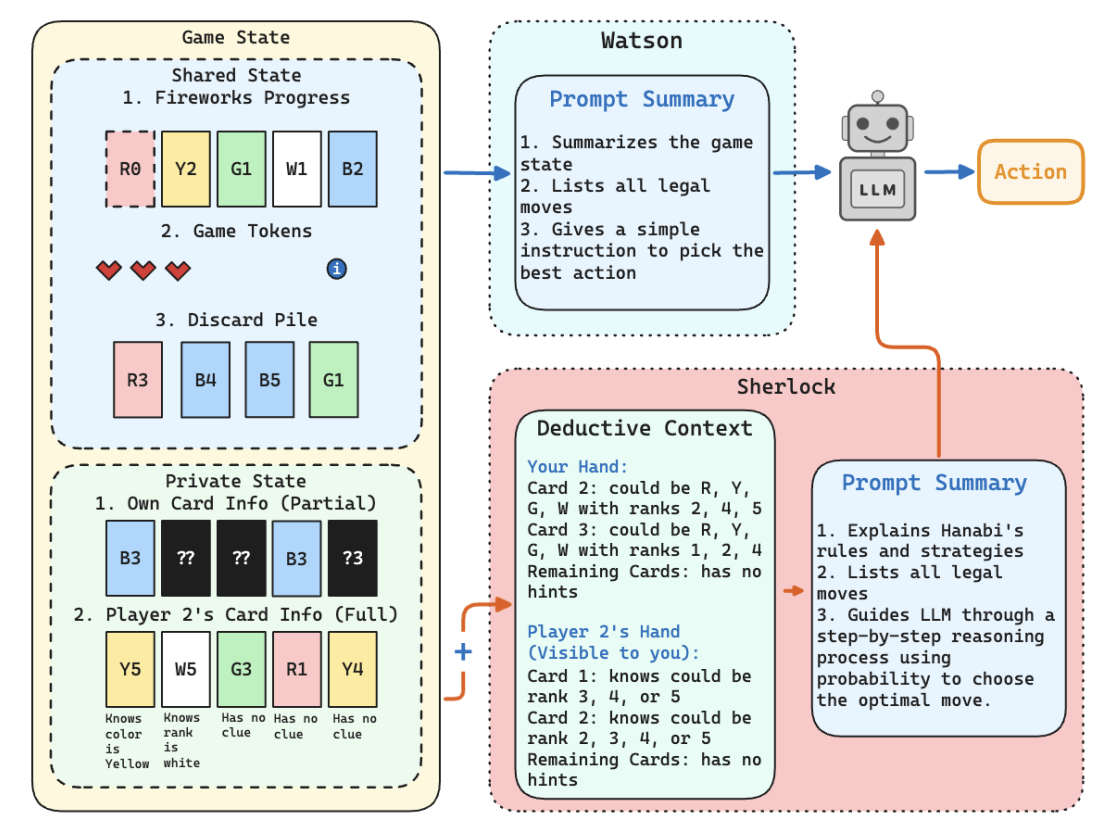
Sparks of Cooperative Reasoning: LLMs as Strategic Hanabi Agents
We benchmark 17 LLMs as strategic agents in Hanabi across 2–5 player settings and three scaffolds: Watson, Sherlock, and Mycroft. Our main scaffold, Mycroft, tests whether LLMs can maintain their own evolving belief state across turns without engine-provided deductions. Recent reasoning models show promising cooperative behavior, but still lag behind strong human and specialized Hanabi agents. We also release Hanabi trajectories and move-level judge data for training, and show that a post-trained Qwen3-4B model can substantially close the gap while transferring to other tasks.
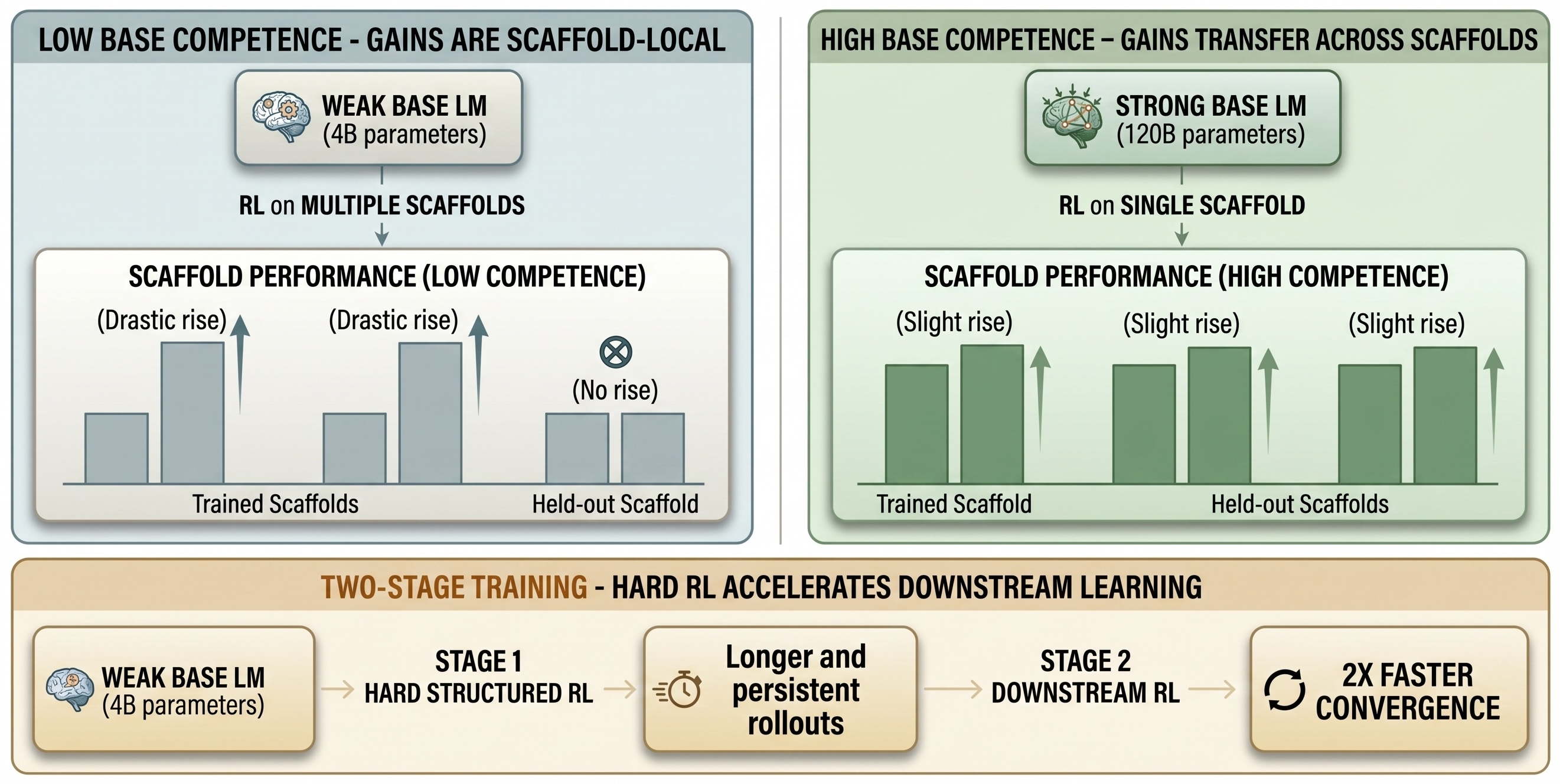
Playing with Fire: What Transfers When RL Trains a Language Agent?
We study what actually transfers when reinforcement learning trains a language agent — separating the skills that generalize to out-of-domain tasks from those that overfit to the training environment.