 Sparks of Cooperative Reasoning: LLMs as Strategic Hanabi Agents
Sparks of Cooperative Reasoning: LLMs as Strategic Hanabi AgentsContributions
- Benchmark 17 LLMs as Hanabi agents across 2–5 player settings.
- Introduce Mycroft, a scaffold for implicit multi-turn state tracking.
- Study self-play, cross-play, best-of-K, and mixture-of-agent settings.
- Release trajectories and move-rated data for SFT/RL training.
- Post-train Qwen3-4B and show gains in Hanabi and transfer tasks.
🗂️ Released data
- • HanabiLogs: LLM gameplay trajectories for SFT
- • HanabiRewards: move-level ratings / judge scores for RL-style training
- • Models include o3, Gemini 2.5 Pro, o4-mini, Grok, DeepSeek, Qwen, and others.
Why Hanabi
Cooperative coordination under partial information is the part of intelligence that single-agent benchmarks miss. Hanabi is the canonical testbed: 2 to 5 players hold cards facing outward, visible to everyone but themselves, and must build five color-ordered “fireworks” using only color or rank hints from a finite pool of information tokens. Success requires tracking hidden information, inferring teammate intent, and coordinating through sparse signals.
Specialized RL agents reach ~24/25 in 2-player self-play but degrade sharply with more players or unfamiliar partners. We ask a different question: how good are general-purpose LLMs as cooperative agents, and what limits them?
Three scaffolds
We progressively scale the context an agent receives, from minimal state to engine-provided deductions to fully implicit multi-turn state tracking. Each scaffold isolates a different capability.
Watson
Minimal context: game state, visible hands, and explicit knowledge from clues. Nothing else. This establishes a lower bound on what LLMs can do without scaffolding.
Sherlock
Adds engine-computed deductive context (per-card "could be" possibilities), Hanabi strategy notes, and a Bayesian step-by-step prompt. Establishes an upper bound with rich prefill.
Mycroft
No engine deductions. The agent must implicitly track its own and teammates' beliefs across turns via a structured "scratch pad," closer to how humans actually play.
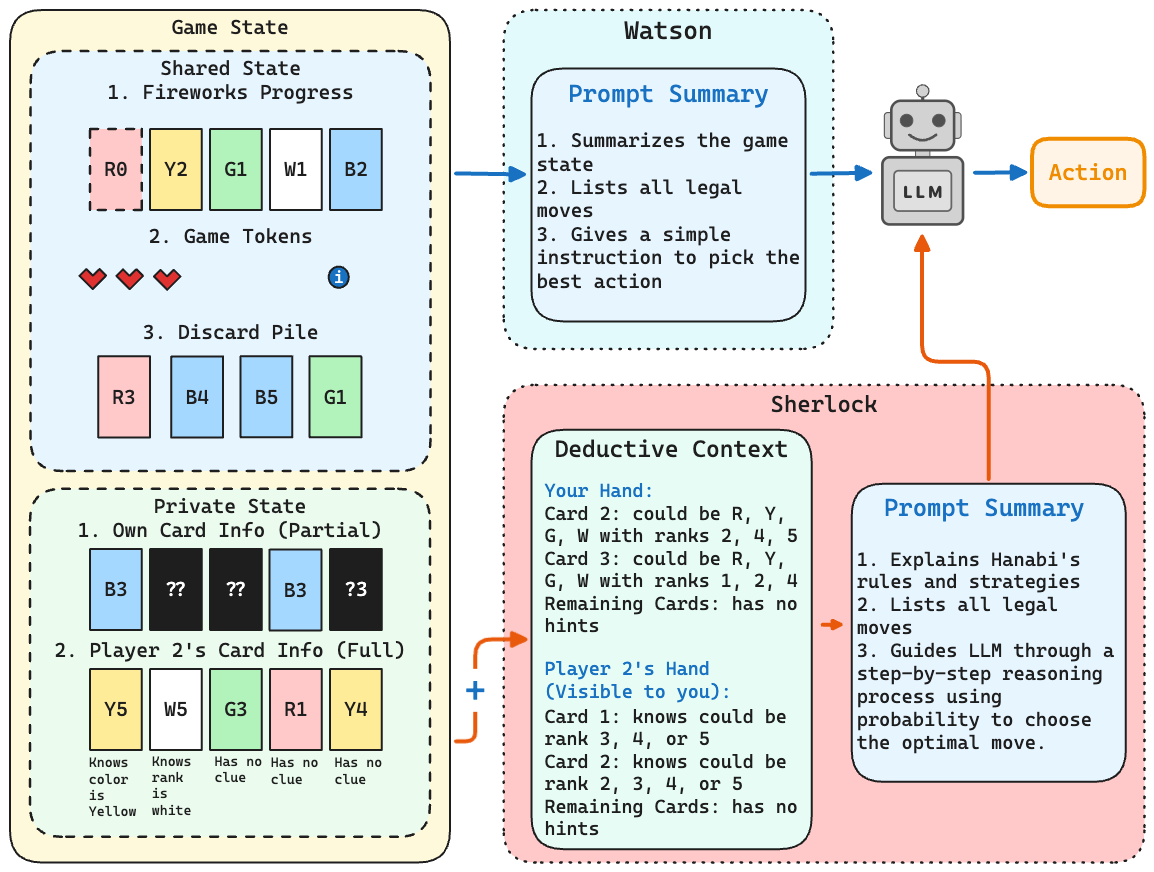
Watson & Sherlock
Watson and Sherlock differ in one thing: whether the agent receives a programmatic belief state. Sherlock’s deductive context lists, for every card in every hand, the colors and ranks still consistent with the clue history. The agent is then prompted to do Bayesian-style probability reasoning over those candidates before acting.
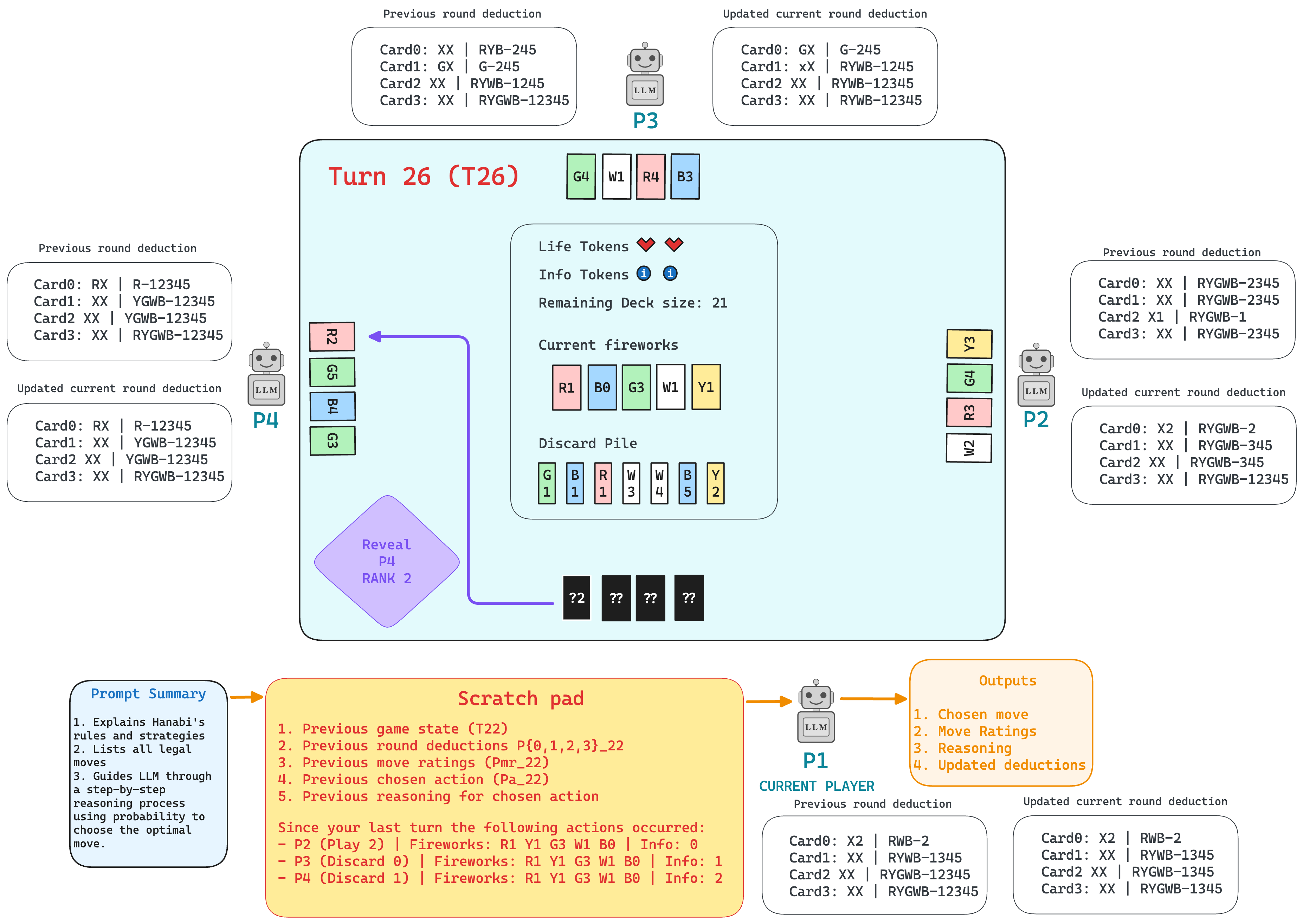
Mycroft
Mycroft removes the engine crutch. Each turn, the agent receives the previous turn’s game state, its own deductions for every player, move ratings, chosen action, and reasoning. It must then produce updated deductions, ratings, and an action. This forces the model to be its own Hanabi Learning Environment, tracking belief shifts and card position changes (cards slide left after a play or discard) across 60+ turns.
Benchmark results
We evaluate 17 LLMs (4B to 600B+, both reasoning and non-reasoning) across 2 to 5 player self-play, with 10 fixed seeds per configuration. Reasoning models clear ~13/25 in Watson; non-reasoning models mostly stall below 10/25.
| Model | 2-Player | 3-Player | 4-Player | 5-Player |
|---|---|---|---|---|
| Mistral Medium 3 | 2.2 | 1.9 | 1.7 | 1.2 |
| Gemini 2.0 Flash | 4.5 | 3.7 | 3.3 | 3.6 |
| Llama-4 Maverick | 3.8 | 4.4 | 5.9 | 4.8 |
| GPT-4o | 5.3 | 4.6 | 5.3 | 4.9 |
| DeepSeek-V3 | 5.9 | 6.3 | 4.3 | 5.0 |
| GPT-4.1 mini | 10.8 | 8.3 | 8.2 | 7.2 |
| Claude Sonnet 3.7 | 10.7 | 9.2 | 8.5 | 6.9 |
| Qwen-32B | 9.9 | 9.0 | 8.8 | 9.2 |
| Grok-3 | 9.9 | 10.6 | 9.3 | 8.0 |
| GPT-4.1 | 12.1 | 11.8 | 10.0 | 8.2 |
| Gemini 2.5 Flash | 12.8 | 13.8 | 13.0 | 12.7 |
| Gemini 2.5 Pro | 13.2 | 13.9 | 12.9 | 12.9 |
| Qwen-235B-A22B | 15.0 | 14.6 | 13.0 | 12.9 |
| Grok-3 Mini | 14.2 | 13.9 | 14.5 | 14.8 |
| DeepSeek-R1 | 14.2 | 15.3 | 14.1 | 13.4 |
| o4-mini | 15.0 | 15.5 | 14.5 | 13.9 |
| o3 | 15.9 | 15.3 | 16.4 | 13.9 |
| Model | 2-Player | 3-Player | 4-Player | 5-Player |
|---|---|---|---|---|
| Mistral Medium 3 | 4.1 | 4.8 | 5.3 | 5.4 |
| Gemini 2.0 Flash | 4.2 | 3.3 | 4.0 | 4.3 |
| Llama-4 Maverick | 4.9 | 5.2 | 5.4 | 5.6 |
| GPT-4o | 4.4 | 4.1 | 4.5 | 4.6 |
| DeepSeek-V3 | 3.9 | 4.2 | 5.4 | 5.8 |
| GPT-4.1 mini | 6.5 | 6.1 | 5.1 | 5.8 |
| Claude Sonnet 3.7 | 5.4 | 5.4 | 5.4 | 5.6 |
| Qwen-32B | 5.6 | 13.1 | 5.4 | 12.1 |
| Grok-3 | 12.8 | 8.0 | 13.3 | 5.6 |
| GPT-4.1 | 14.8 | 16.4 | 15.5 | 14.4 |
| Gemini 2.5 Flash | 8.4 | 6.6 | 7.7 | 5.6 |
| Gemini 2.5 Pro | 12.8 | 16.2 | 16.9 | 14.4 |
| Qwen-235B-A22B | 14.6 | 16.6 | 16.7 | 13.3 |
| Grok-3 Mini | 14.4 | 16.6 | 17.4 | 15.5 |
| DeepSeek-R1 | 17.5 | 16.6 | 15.6 | 15.1 |
| o4-mini | 14.6 | 18.0 | 14.1 | 13.0 |
| o3 | 17.6 | 17.6 | 16.8 | 15.7 |
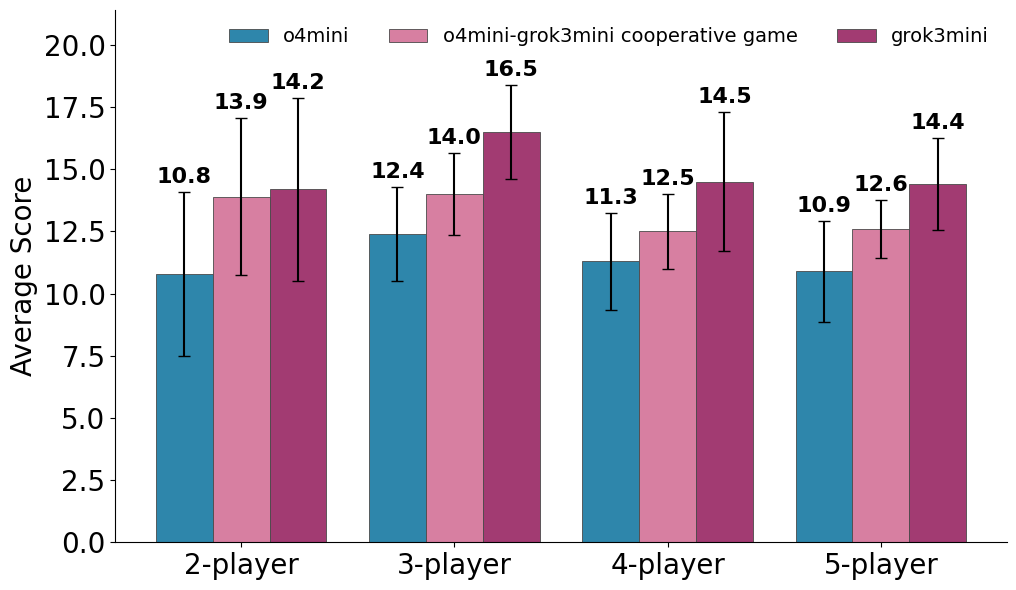
| Model | 2-Player | 3-Player | 4-Player | 5-Player |
|---|---|---|---|---|
| o4-mini | 10.8 | 12.4 | 11.3 | 10.9 |
| Grok-3 Mini | 14.2 | 16.5 | 14.5 | 14.4 |
| Gemini 2.5 Pro | 10.2 | 13.4 | 14.1 | 11.6 |
| Gemini 2.5 Flash | 11.8 | 13.2 | 12.3 | 9.8 |
| o3 | 16.3 | 16.4 | 15.5 | 14.7 |
Ablations
Cross-play
Self-play is generous; real cooperation is ad hoc. We compose teams with one Grok-3-mini agent and the rest o4-mini (the weaker model in Mycroft, 14.9 vs 11.3). Across all 2 to 5 player settings, adding one stronger agent lifts team scores by ~1.7 points. Performance smoothly interpolates between the weak and strong self-play baselines, unlike specialized RL agents which collapse with unfamiliar partners.
Best-of-K
Sample the agent K times per turn and ask it to pick its best candidate. With Watson, performance climbs through K=5 (+1.5 on average) then plateaus. With Sherlock, gains are negligible (+0.1) because a well-engineered prompt mostly converges to the same action across samples, so naive scaling does not help. Better context beats more samples.
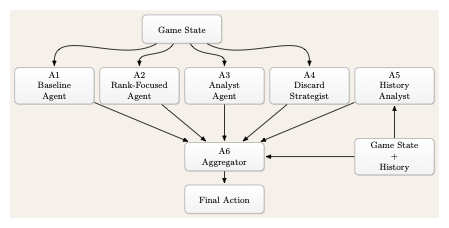
Mixture of agents
To break sample homogeneity, we run five role-specialized agents in parallel (Baseline, Rank-Focused, Analyst, Discard Strategist, History Analyst) and aggregate their proposals via a sixth "finalizer" agent.
MoA modestly improves the 5-player setting (+1.1 with Watson, +0.8 with Sherlock over Best-of-5) but introduces high variance: speculative agents (especially the History Analyst) occasionally mislead the aggregator and tank a run. Diversity helps when it lands; reliability remains the open problem.
Post-training: closing the gap with a 4B model
To validate our datasets, we post-train Qwen3-4B-Instruct-2507, a small non-reasoning model, on data collected from o3 and Grok-3-mini.
- HanabiLogs (1,520+ trajectories): used for supervised finetuning.
- HanabiRewards (560+ games with dense move-level utility annotations): used for RLVR via GRPO.
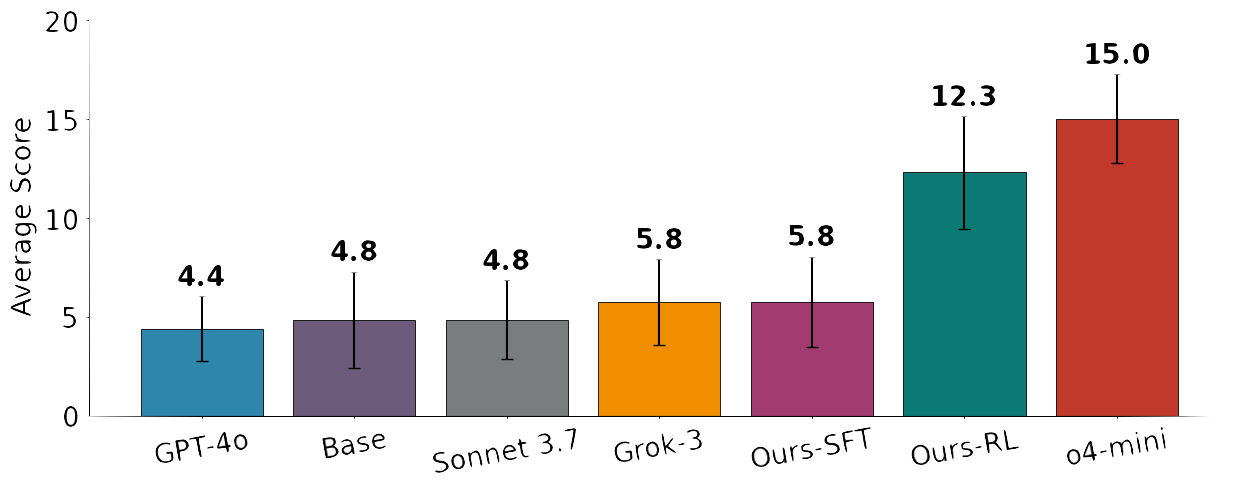
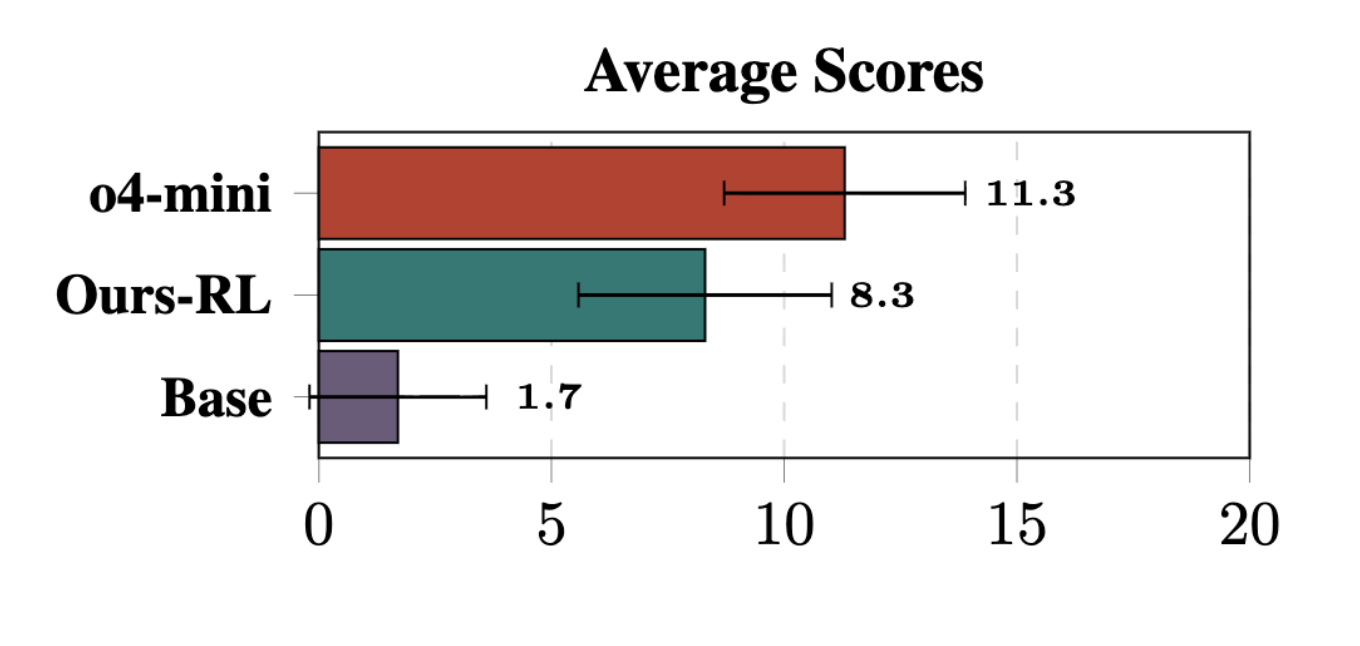
The base model scores 1.7 in Mycroft. After RL on HanabiRewards it reaches 8.3, a +388% jump that lands within ~3 points of o4-mini (11.3) and surpasses GPT-4.1 (the best non-reasoning baseline) by +88%. In Sherlock, the same model jumps from 4.8 to 12.3 (+156%), comparable to Grok-3 and beating GPT-4o.
Generalization beyond Hanabi
The interesting result isn’t just “we got better at Hanabi.” Training on HanabiRewards transfers to four out-of-domain benchmarks, with no degradation on math.
| Model | Group Guess (1st / 2nd run) |
EventQA (64K / 128K / 800K) |
IFBench (Avg / Pass@10) |
AIME 2025 (Avg / Pass@10) |
|---|---|---|---|---|
| Base | 61.0 / 60.5 | 84.0 / 62.6 / 37.2 | 30.9 / 42.9 | 48.7 / 73.3 |
| Ours-RL | 73.0 / 71.5 | 85.6 / 66.8 / 43.6 | 31.5 / 44.6 | 50.0 / 73.3 |
| Δ | +12.0 / +11.0 | +1.6 / +4.2 / +6.4 | +0.6 / +1.7 | +1.3 / +0.0 |
The temporal-reasoning lift on EventQA grows with context length (+1.6, +4.2, +6.4 from 64K to 800K), which we read as evidence that learning to implicitly track Hanabi state generalizes to long-horizon belief tracking elsewhere. AIME stays flat, with no catastrophic forgetting on math.
Takeaways
- Modern reasoning LLMs show sparks of cooperative reasoning, but reliable multi-agent coordination remains unsolved. The best score ~15 to 18/25 in self-play, comfortably below specialized agents (>23) and the median human Hanabi player (~18 to 21).
- Scaffold design matters more than model scale. Moving from Watson to Sherlock improves reasoning models by +2.0 on average; the same scaffold hurts most non-reasoning models. Different families respond differently to identical context.
- Implicit state tracking is the open problem. Even o3 drops 1.2 points moving from engine-provided deductions to self-tracking; Gemini 2.5 Pro drops 3.7. Multi-turn belief maintenance is where current models break.
- Cross-play is graceful. Unlike specialized RL agents, LLMs interpolate smoothly between weak and strong teammates, showing a small but real “spark” of cooperative generalization.
- A 4B model can carry surprising weight. Post-training on our datasets closes most of the gap to frontier reasoning models on Hanabi and transfers to temporal reasoning, instruction following, and out-of-domain cooperation.
Citation
@misc{ramesh2026sparkscooperativereasoningllms,
title={Sparks of Cooperative Reasoning: LLMs as Strategic Hanabi Agents},
author={Mahesh Ramesh and Kaousheik Jayakumar and Aswinkumar Ramkumar and Pavan Thodima and Aniket Rege and Emmanouil-Vasileios Vlatakis-Gkaragkounis},
year={2026},
eprint={2601.18077},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2601.18077},
}