Sparks of Cooperative Reasoning: LLMs as Strategic Hanabi Agents
We benchmark 17 LLMs as strategic agents in Hanabi across 2–5 player settings and three scaffolds: Watson, Sherlock, and Mycroft. Our main scaffold, Mycroft, tests whether LLMs can maintain their own evolving belief state across turns without engine-provided deductions. Recent reasoning models show promising cooperative behavior, but still lag behind strong human and specialized Hanabi agents. We also release Hanabi trajectories and move-level judge data for training, and show that a post-trained Qwen3-4B model can substantially close the gap while transferring to other tasks.

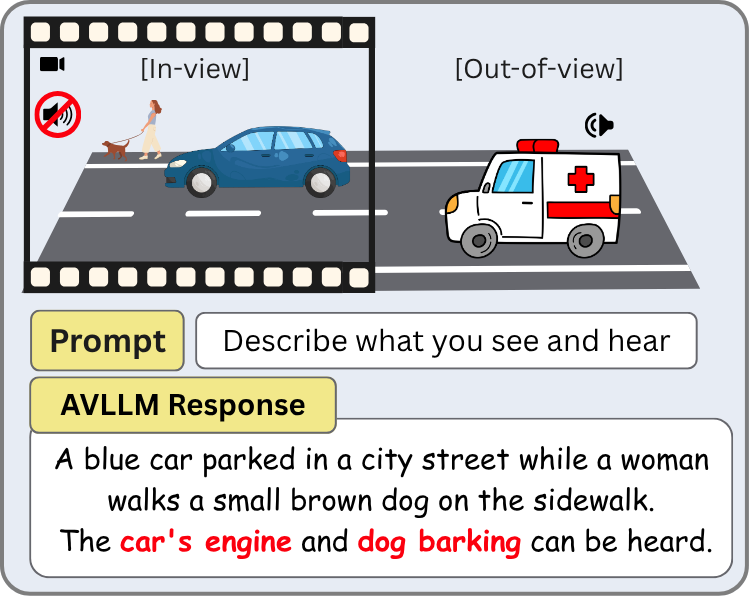
Do Audio-Visual Large Language Models Really See and Hear?
AVLLMs exhibit a strong vision bias in audio understanding, hallucinating sounds from what they see rather than what they hear. We conduct mechanistic interpretability experiments showing that rich audio semantics exist internally, cross-modal transfer occurs in mid-to-deep layers where vision dominates, and this bias likely stems from vision-centric training.